
개요
개선을 경험한 내용을 공유하고자 합니다. 프로젝트에서 쿼리 성능을 개선하기 위해 `GROUP BY`와 `JOIN`의 순서를 바꿔 NL(Nested Loop) JOIN의 드라이빙 테이블 크기를 줄이고, 인덱스를 활용한 정렬이 깨지지 않도록 개선하였습니다. 그리고 서브 쿼리에서 커버링 인덱스를 적용했습니다. 최종적으로 `GROUP BY` + `HAVING` 을 여러 개의 `JOIN` 으로 변환해 임시 테이블 없이 인덱스를 더 잘 활용하도록 개선하였습니다. 이 과정을 통해 **쿼리 성능을 최대 722배 개선**할 수 있었습니다.
이 글에서는 정렬 시 인덱스를 활용하는 것이 중요하지만, 드라이빙 테이블의 크기가 쿼리 성능에 미치는 영향이 더 클 수 있다는 사실을 다룹니다.
또한 커버링 인덱스에서 복합 인덱스를 거는 순서에 따라 끼치는 영향에 대해 다룹니다. 이 과정에서 첫번째 컬럼의 카디널리티가 Index Skip Scan 성능에 끼치는 영향을 다룹니다.
투룻 서비스 소개
투룻은 여행기 서비스로, 여행기에 달려있는 태그 기반으로 여행기 목록을 조회하는 기능이 있었습니다. 이 때 여행기 목록은 좋아요 순으로 정렬되어 표시되었습니다.
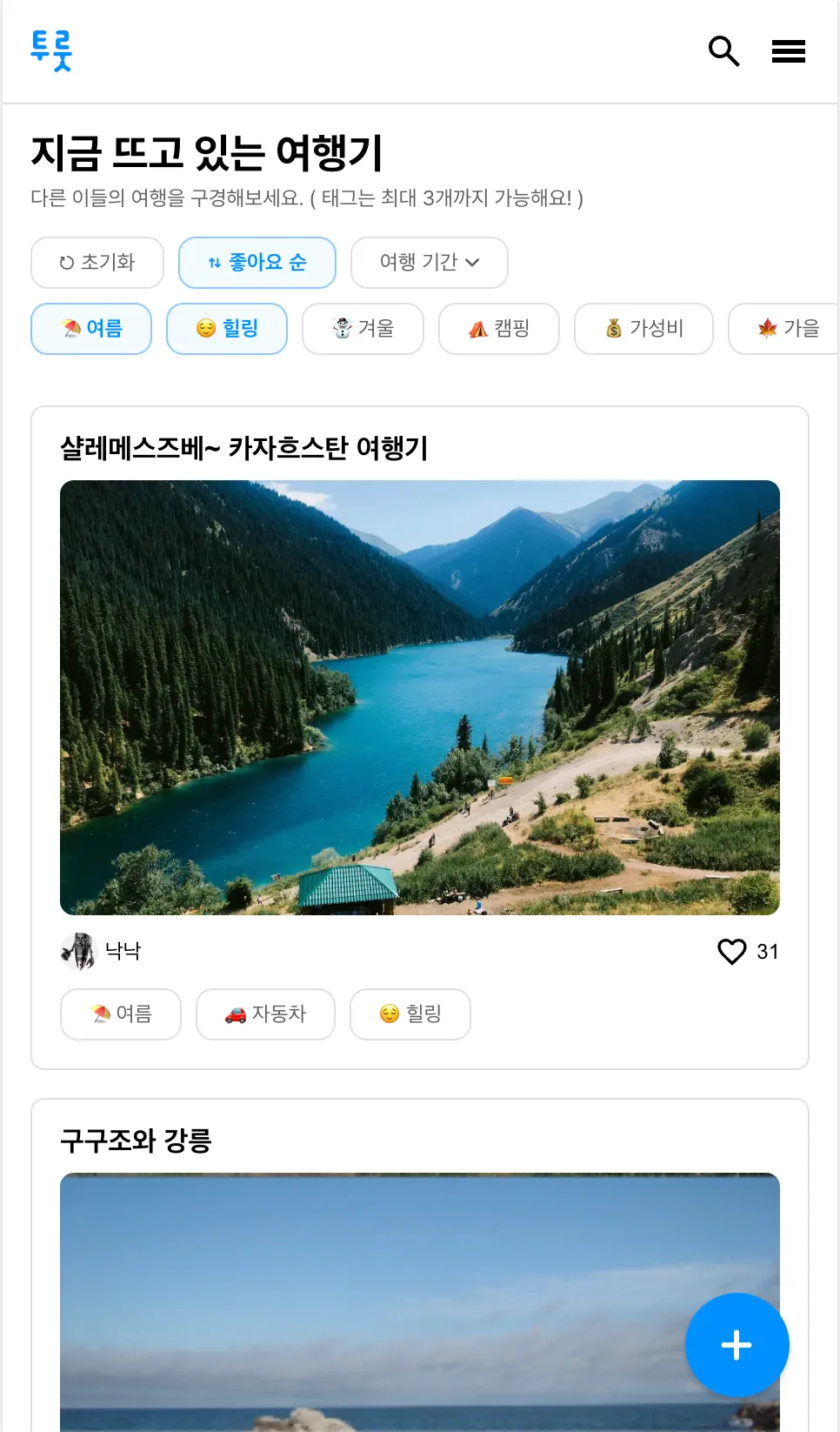
위의 화면은 태그 기반으로 좋아요 순으로 정렬한 여행기 목록을 보여줍니다.
간략한 테이블 구조 설명
쿼리를 살피기 전에 테이블 구조를 간략하게 설명하겠습니다. 기본적으로 여행기 정보를 저장하는 travelogue 테이블과 태그 정보를 저장하는 tag 테이블이 있습니다. 여행기에는 여러 개의 태그가 존재할 수 있기 때문에 다대다 관계로 중간 테이블인 travelogue_tag 테이블이 존재합니다.
또한 travelogue 테이블에는 like_count라는 좋아요 숫자에 대한 컬럼이 반정규화되어 존재했습니다. 이는 좋아요 순 정렬 성능을 높이기 위해 추가된 컬럼입니다.
기존 쿼리
이 때 태그로 필터링 후 좋아요 순으로 정렬하는 쿼리를 다음과 같이 작성하였습니다.
SELECT
t1_0.id,
t1_0.author_id,
t1_0.created_at,
t1_0.deleted_at,
t1_0.like_count,
t1_0.modified_at,
t1_0.thumbnail,
t1_0.title
FROM
travelogue t1_0
JOIN
travelogue_tag tt1_0
ON tt1_0.travelogue_id = t1_0.id
WHERE
tt1_0.tag_id IN (?, ?)
GROUP BY
tt1_0.travelogue_id
HAVING
COUNT(tt1_0.id) = ?
ORDER BY
t1_0.like_count DESC
LIMIT ? OFFSET ?;여기서 travelogue와 travelogue_tag 테이블을 JOIN한 후, GROUP BY와 HAVING을 사용하여 선택한 태그를 전부 가지고 있는 여행기를 필터링하였습니다. 이후 like_count로 내림차순 정렬하고, LIMIT과 OFFSET을 사용하여 반환하였습니다. 이 때 LIMIT과 OFFSET은 무한 스크롤을 구현하기 위해 페이지 개수만큼 데이터를 자르는 방식으로 사용되었습니다.
해당 쿼리의 실행 계획을 살펴보았더니 다음과 같이 Using temporary; Using filesort가 있는 것을 확인할 수 있었습니다.
+--+-----------+-----+----------+------+---------------------------------------------------------+-------+-------+--------------------------------+-------+--------+--------------------------------------------+
|id|select_type|table|partitions|type |possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+------+---------------------------------------------------------+-------+-------+--------------------------------+-------+--------+--------------------------------------------+
|1 |SIMPLE |tt1_0|null |ALL |fk_travelogue_tag_tag_id,fk_travelogue_tag_travelogue_id |null |null |null |1495116|20.61 |Using where; Using temporary; Using filesort|
|1 |SIMPLE |t1_0 |null |eq_ref|PRIMARY,fk_travelogue_author_id,idx_travelogue_like_count|PRIMARY|8 |touroot_test.tt1_0.travelogue_id|1 |100 |null |
+--+-----------+-----+----------+------+---------------------------------------------------------+-------+-------+--------------------------------+-------+--------+--------------------------------------------+like_count 컬럼에 대한 인덱스가 있었지만, 옵티마이저는 이 인덱스를 활용하지 않고 직접 정렬하는 계획을 선택하였습니다. 인덱스를 활용하지 못했기 때문에 성능 저하가 우려되었고, 이에 따라 테스트 데이터를 넣고 성능을 측정하였습니다.
테스트 데이터 정보
테스트를 위해 travelogue 데이터 100만 건, 태그 17개, 여행기 당 평균 태그 1.5개, 여행기 당 좋아요 수 평균 50개로 설정하고 성능을 측정하였습니다. 실제 환경과의 차이를 조금이라도 줄이기 위해 단순 랜덤으로 데이터를 생성하지 않고, 정규 분포 형태로 데이터를 생성하여 측정하였습니다.
테스트 결과
그 결과 평균 1.445초가 소요되었습니다. 이는 단순히 슬로우 쿼리일 뿐만 아니라, 인덱스를 제대로 활용하지 못한 것이 원인이었기에 100ms 이내로 개선하는 것을 목표로 쿼리 튜닝을 시작했습니다.
실행 계획을 확인해 보니 옵티마이저는 travelogue_tag를 드라이빙 테이블로 선택하고 있었습니다. 그러나 저는 travelogue의 (like_count) 인덱스를 드라이빙 테이블로 사용하는 것이 더 효율적이라고 판단했습니다. (like_count) 인덱스에서 row를 하나씩 가지고 와 travelogue_tag와 조인을 수행하면 그 결과는 like_count 순으로 정렬될 것이기 때문입니다.
travelogue를 강제로 드라이빙 테이블로 삼아보자
따라서 STRAIGHT_JOIN을 사용하여 travelogue를 강제적으로 드라이빙 테이블로 삼고 쿼리를 실행했으나, 실행 시간이 4s가 걸리는 결과를 초래했습니다. 실행 계획을 확인해보니 드라이빙 테이블로 (like_count) 인덱스가 아닌 PK 인덱스를 활용하는 것을 확인할 수 있었습니다.
-> Limit: 5 row(s) (actual time=3994..3994 rows=5 loops=1)
-> Sort: t1_0.like_count DESC (actual time=3994..3994 rows=5 loops=1)
-> Filter: (`count(tt1_0.id)` = 2) (actual time=1.73..3985 rows=7396 loops=1)
-> Stream results (cost=1.79e+6 rows=489639) (actual time=1.01..3974 rows=170101 loops=1)
-> Group aggregate: count(tt1_0.id) (cost=1.79e+6 rows=489639) (actual time=0.965..3888 rows=170101 loops=1)
-> Nested loop inner join (cost=1.68e+6 rows=489639) (actual time=0.939..3822 rows=177497 loops=1)
-> Index scan on t1_0 using PRIMARY (cost=107101 rows=990317) (actual time=0.614..568 rows=1e+6 loops=1)
-> Filter: (tt1_0.tag_id in (2,5)) (cost=1.38 rows=0.494) (actual time=0.00306..0.00314 rows=0.177 loops=1e+6)
-> Index lookup on tt1_0 using fk_travelogue_tag_travelogue_id (travelogue_id = t1_0.id) (cost=1.38 rows=2.01) (actual time=0.00267..0.00294 rows=1.5 loops=1e+6)위의 실행 계획에서 Index scan on t1_0 using PRIMARY 를 통해 PK 인덱스를 드라이빙 테이블로 삼는 것을 확인할 수 있습니다.
(like_count) 인덱스를 통해 정렬된 순서로 travelogue row를 읽어온다 해도, GROUP BY travelogue.id가 집계 처리를 위해 임시 테이블을 생성하면서 정렬 상태는 깨지게 됩니다.
즉 GROUP BY와 ORDER BY의 기준 컬럼이 서로 다르기 때문에 결국 (like_count) 인덱스를 사용하더라도 그 정렬 순서가 최종 결과에 유지되지 못합니다.
따라서 옵티마이저는 어차피 정렬해야 하기 때문에 (like_count) 인덱스에 접근해서 룩업을 하기보단 클러스터드 인덱스에 접근하는 것을 선택하는 것으로 볼 수 있습니다.
그리고 위의 실행 계획이 더 느린 이유는 드라이빙 테이블의 크기가 더 크기 때문입니다. 위의 실행 계획에서 travelogue의 모든 row를 가져오기 때문에 드라이빙 테이블의 크기가 100만 개임을 확인할 수 있습니다. 따라서 travelogue_tag 를 드라이빙 테이블로 삼는 것보다 더 느린 것입니다.
실제로 travelogue_tag를 드라이빙 테이블로 삼는 실행 계획을 확인해보니, 드라이빙 테이블의 크기가 약 17만 개임을 알 수 있었습니다.
(드라이빙 테이블이 커지면 읽어야 하는 row 개수 자체도 많아지고, 또한 디스크에서 랜덤 I/O가 많이 발생하기 때문에 성능이 저하됩니다. 관련된 내용은 자세히 설명하지 않겠습니다.)
-> Limit: 5 row(s) (actual time=1713..1713 rows=5 loops=1)
-> Sort: t1_0.like_count DESC (actual time=1713..1713 rows=5 loops=1)
-> Filter: (`count(tt1_0.id)` = 2) (actual time=1647..1707 rows=7255 loops=1)
-> Table scan on <temporary> (actual time=1647..1699 rows=169368 loops=1)
-> Aggregate using temporary table (actual time=1647..1647 rows=169367 loops=1)
-> Nested loop inner join (cost=416899 rows=315298) (actual time=1.58..1105 rows=176623 loops=1)
-> Filter: (tt1_0.tag_id in (2,5)) (cost=152507 rows=315298) (actual time=0.872..495 rows=176623 loops=1)
-> Table scan on tt1_0 (cost=152507 rows=1.5e+6) (actual time=0.792..415 rows=1.5e+6 loops=1)
-> Single-row index lookup on t1_0 using PRIMARY (id=tt1_0.travelogue_id) (cost=0.739 rows=1) (actual time=0.00327..0.0033 rows=1 loops=176623)travelogue_tag 를 드라이빙 테이블로 삼으면, 위의 실행 계획에 나와 있듯 Filter: (tt1_0.tag_id in (2,5)) 를 먼저 수행 후 JOIN 하기 때문에 드라이빙 테이블의 크기가 줄어들어 성능이 더 좋은 것입니다.
첫번째 쿼리 개선 - GROUP BY와 JOIN의 순서를 바꿔보자
GROUP BY를 먼저 수행한 후 JOIN을 하도록 아래와 같이 쿼리를 수정해 보았습니다.
SELECT t.id,
t.author_id,
t.created_at,
t.deleted_at,
t.like_count,
t.modified_at,
t.thumbnail,
t.title
FROM travelogue t
JOIN
(SELECT tt.travelogue_id
FROM travelogue_tag tt
WHERE tt.tag_id IN (?, ?)
GROUP BY tt.travelogue_id
HAVING COUNT(tt.id) = ?) st
ON t.id = st.travelogue_id
ORDER BY t.like_count DESC
LIMIT ? OFFSET ?;그 이유는 두가지 때문이었습니다.
- travelogue의 (like_count) 인덱스를 드라이빙 테이블로 삼는 경우,
JOIN전에GROUP BY를 수행하기 때문에 마지막까지 정렬된 상태가 유지됩니다. 따라서 추가적인 정렬 작업이 필요 없게 됩니다. - 반대로 travelogue_tag를 드라이빙 테이블로 사용할 경우, GROUP BY와 HAVING 절을 먼저 적용해 드라이빙 테이블의 row 수 자체를 줄일 수 있습니다.
드라이빙 테이블을 travelogue로 설정한 경우
다음은 실행 계획입니다.
-> Limit: 5 row(s) (cost=2.48e+6 rows=0) (actual time=325..326 rows=5 loops=1)
-> Nested loop inner join (cost=2.48e+6 rows=0) (actual time=325..326 rows=5 loops=1)
-> Index scan on t using idx_travelogue_like_count (cost=0.0108 rows=1) (actual time=0.0201..1.12 rows=446 loops=1)
-> Covering index lookup on ttt using <auto_key0> (travelogue_id=t.id) (cost=0.25..2.5 rows=10) (actual time=0.729..0.729 rows=0.0112 loops=446)
-> Materialize (cost=0..0 rows=0) (actual time=325..325 rows=7255 loops=1)
-> Filter: (`count(tt.id)` = 2) (actual time=299..322 rows=7255 loops=1)
-> Table scan on <temporary> (actual time=299..314 rows=169368 loops=1)
-> Aggregate using temporary table (actual time=299..299 rows=169368 loops=1)
-> Index range scan on tt using fk_travelogue_tag_tag_id over (tag_id = 2) OR (tag_id = 5), with index condition: (tt.tag_id in (2,5)) (cost=141885 rows=315298) (actual time=0.0183..218 rows=176623 loops=1)실행 계획을 보면 더 이상 like_count에 대해 정렬을 수행하지 않는 것을 확인할 수 있습니다. (2번째 줄에 있던 Sort: t1_0.like_count DESC이 더이상 없습니다.)
(like_count) 인덱스에서 순서대로 row를 읽고, 조건에 맞는 5개를 찾을 때까지만 JOIN을 수행하게 됩니다.
실제 row 수는 446개로 이전보다 훨씬 적게 읽는 것을 확인할 수 있습니다.
결과적으로 실행 시간은 약 300ms로 줄어들어, 이전보다 약 6배 이상 성능이 개선되었습니다. 이는 Using temporary; Using filesort 로 직접 정렬하지 않고 (like_count) 인덱스를 활용하여 정렬했기 때문이며, 동시에 드라이빙 테이블의 크기도 많이 줄어들었기 때문입니다.
하지만 OFFSET을 1000까지 늘리면 쿼리는 다시 1.4초로 많이 느려졌습니다. 실행 계획을 보니 OFFSET이 증가하게 되면서 travelogue에서 많은 row를 가져와 JOIN을 수행해야 했기 때문에 느려진 것이었습니다. 확인해보니 OFFSET 1000 기준으로 약 14만 개 정도의 row를 가져오는 것을 확인하였습니다.
드라이빙 테이블을 travelogue_tag로 설정한 경우
OFFSET이 1000인 경우에는 travelogue_tag를 드라이빙 테이블로 삼은 실행 계획이 약 500ms 정도로 오히려 더 빠른 것을 확인할 수 있었습니다. 이는 드라이빙 테이블의 크기 때문이었습니다. 다음은 실행 계획입니다.
-> Limit/Offset: 5/1000 row(s) (actual time=577..577 rows=5 loops=1)
-> Sort: t.like_count DESC, limit input to 1005 row(s) per chunk (actual time=577..577 rows=1005 loops=1)
-> Stream results (cost=226260 rows=0) (actual time=396..568 rows=7255 loops=1)
-> Nested loop inner join (cost=226260 rows=0) (actual time=396..561 rows=7255 loops=1)
-> Table scan on ttt (cost=2.5..2.5 rows=0) (actual time=396..397 rows=7255 loops=1)
-> Materialize (cost=0..0 rows=0) (actual time=396..396 rows=7255 loops=1)
-> Filter: (`count(tt.id)` = 2) (actual time=373..395 rows=7255 loops=1)
-> Table scan on <temporary> (actual time=373..388 rows=169368 loops=1)
-> Aggregate using temporary table (actual time=373..373 rows=169368 loops=1)
-> Index range scan on tt using fk_travelogue_tag_tag_id over (tag_id = 2) OR (tag_id = 5), with index condition: (tt.tag_id in (2,5)) (cost=166165 rows=315298) (actual time=0.373..279 rows=176623 loops=1)
-> Single-row index lookup on t using PRIMARY (id=ttt.travelogue_id) (cost=0.718 rows=1) (actual time=0.0223..0.0224 rows=1 loops=7255)인덱스를 활용하지 않고 직접 정렬(Using temporary; Using filesort)을 하지만, 드라이빙 테이블의 크기를 보면 row 수가 7255 개인 것을 확인할 수 있습니다. 이는 WHERE 조건뿐만 아니라, GROUP BY와 HAVING 절까지 먼저 적용되어 JOIN 전에 불필요한 row 수가 대폭 줄어들었기 때문입니다. 따라서 OFFSET 이 큰 경우에는 직접 정렬하는 것이 (like_count) 인덱스를 활용하는 것보다 오히려 더 빠른 결과를 보였습니다.
이를 통해 드라이빙 테이블의 크기가 쿼리에 얼마나 큰 영향을 미치는지를 알 수 있었습니다.
(Using temporary; Using filesort 가 더 빠를줄이야..)
두번째 쿼리 개선 - 서브 쿼리 개선(커버링 인덱스)
이번에는 서브 쿼리를 개선하였습니다.
SELECT tt.travelogue_id
FROM travelogue_tag tt
WHERE tt.tag_id IN (?, ?)
GROUP BY tt.travelogue_id
HAVING COUNT(tt.id) = ?)위의 쿼리를 보면 다음과 같이 3개의 컬럼을 사용하는 것을 확인할 수 있습니다.
- travelogue_id (
SELECT,GROUP BY) - tag_id (
WHERE) - id (
HAVING)
현재 travelogue_tag 테이블에는 외래 키로 인해 각각 travelogue_id와 tag_id에 대해 개별 인덱스가 존재하지만, 이 인덱스들 중 어느 것도 세 컬럼을 모두 포함하고 있지 않기 때문에 결국 클러스터드 인덱스를 통한 테이블 룩업이 발생합니다.
이를 해결하기 위해 커버링 인덱스를 적용하기로 결정했고 tag_id와 travelogue_id로 구성된 복합 인덱스를 추가했습니다.
이때 인덱스 순서를 (tag_id, travelogue_id)로 설정한 이유는 WHRER 절에 의해 tag_id로 먼저 필터링을 수행한 뒤 travelogue_id 기준으로 GROUP BY 하기 때문입니다. 즉 tag_id 로 필터링을 먼저하기 때문에 복합 인덱스에서 tag_id가 먼저 와야 더 효율적입니다.
바로 다음에 나오는 개선에서 위의 순서로 복합 인덱스를 구성해야 더 효율적으로 동작하게 되는데, 이는 뒤에서 자세히 설명하겠습니다.
인덱스 적용 이후 실행 계획을 확인해보면, 아래와 같이 커버링 인덱스를 활용한 것으로 나타납니다.
-> Filter: (`count(tt.id)` = 2) (actual time=148..170 rows=7255 loops=1)
-> Table scan on <temporary> (actual time=148..162 rows=169368 loops=1)
-> Aggregate using temporary table (actual time=148..148 rows=169368 loops=1)
-> Filter: (tt.tag_id in (2,5)) (cost=68320 rows=336672) (actual time=0.074..63.6 rows=176623 loops=1)
-> Covering index range scan on tt using idx_travelogue_tag_tag_travelogue over (tag_id = 2) OR (tag_id = 5) (cost=68320 rows=336672) (actual time=0.0723..50.4 rows=176623 loops=1)복합 인덱스를 적용한 후 기존 쿼리 성능을 다시 측정한 결과 다음과 같은 개선이 있었습니다:
| 조건 | 개선 전 | 개선 후 |
|---|---|---|
| OFFSET = 0, 드라이빙 테이블 = like_count | 300ms | 100ms |
| OFFSET = 1000, 드라이빙 테이블 = travelogue_tag | 500ms | 200ms |
복합 인덱스를 통해 테이블 룩업을 제거함으로써 WHERE, GROUP BY, HAVING이 모두 인덱스 내에서 해결될 수 있었고,
그 결과 전체 쿼리 성능이 향상되었습니다.
세번째 쿼리 개선 - 서브 쿼리 개선(GROUP BY 없애기)
하지만 서브 쿼리 개선은 여기서 멈추지 않았습니다.
GROUP BY와 HAVING 절을 사용하는 기존 서브쿼리는 집계 결과를 필터링하기 위해 임시 테이블을 생성하는 구조였습니다.
비록 (tag_id, travelogue_id) 복합 인덱스를 통해 커버링 인덱스를 활용하고 있었지만 GROUP BY 대상이 인덱스의 두 번째 컬럼인 travelogue_id였기 때문에 MySQL은 여전히 임시 테이블 기반의 집계 처리를 사용하고 있었습니다.
반대로 인덱스 순서를 (travelogue_id, tag_id)로 바꾸면 정렬된 상태로 임시 테이블 없이 GROUP BY가 가능하긴 하지만, 이 경우 WHERE tag_id = ? 조건이 인덱스의 두 번째 컬럼에 걸려 Index Skip Scan으로 처리되며 성능이 더 저하되는 문제가 발생합니다. 투룻 서비스에서는 여행기마다 0~3 개의 태그를 가지기 때문에 travelogue_id 의 카디널리티가 높았습니다. Index Skip Scan 에서는 첫번째 선행 컬럼의 카디널리티가 높을수록 스캔해야 하는 양이 많아져 쿼리 성능이 떨어지게 됩니다.
(tag_id, travelogue_id) 인덱스에서 어떻게 하면 두번째 컬럼인 travelogue_id를 잘 활용할 수 있을까 고민하다가 tag_id별로 row를 나눠서 각각의 조건을 가진 JOIN을 수행하면 굳이 GROUP BY 없이도 동일한 travelogue_id를 가진 tag 조합을 구할 수 있겠다는 생각이 들었습니다.
즉, tag_id = 2인 travelogue와 tag_id = 5인 travelogue를 각각 필터링한 뒤 travelogue_id를 기준으로 JOIN하면, 두 태그를 모두 가진 travelogue만 추출할 수 있습니다. 이렇게 하면 임시 테이블도 필요 없고, (tag_id, travelogue_id) 인덱스를 활용하면 Index Skip Scan 도 없어지게 됩니다.
SELECT tt1.travelogue_id
FROM travelogue_tag tt1 JOIN travelogue_tag tt2
ON tt1.travelogue_id = tt2.travelogue_id
WHERE tt1.tag_id = 2 AND tt2.tag_id = 5;실행 계획을 확인해보니 다음과 같았습니다.
-> Nested loop inner join (cost=199667 rows=165984) (actual time=0.255..125 rows=7255 loops=1)
-> Covering index lookup on tt1 using idx_travelogue_tag_tag_travelogue (tag_id=2) (cost=17085 rows=165984) (actual time=0.121..19.1 rows=88238 loops=1)
-> Covering index lookup on tt2 using idx_travelogue_tag_tag_travelogue (tag_id=5, travelogue_id=tt1.travelogue_id) (cost=1 rows=1) (actual time=0.00107..0.00109 rows=0.0822 loops=88238)실행 계획을 확인해보면 커버링 인덱스와 JOIN만으로 처리되고 있음을 확인할 수 있습니다.
임시 테이블 없이 수행되며 tag_id는 복합 인덱스의 첫 번째 컬럼이기 때문에 Index Skip Scan 없이 효율적으로 필터링됩니다.
또한 이 JOIN 결과는 travelogue_id 기준으로 정렬된 상태를 유지하므로, 이후 travelogue 테이블과 travelogue_id를 기준으로 JOIN할 때 드리븐 테이블로 삼는 경우 마치 인덱스처럼 동작하여 좋은 성능을 내게 됩니다.
이 방식은 다음과 같은 추가적인 장점도 가지고 있습니다.
- 투룻 서비스에서 여행기는 최대 3개의 태그만 가질 수 있기 때문에
JOIN도 최대 3번만 일어나며, 즉 무한히JOIN이 발생하지 않습니다. - 인덱스를 추가하게 되는 경우 쓰기 작업에 대해서는 손해가 발생하지만, 위의 경우에는 기존 (tag_id) FK 인덱스를 (tag_id, travelogue_id) 인덱스로 대체하면 되기 때문에 인덱스를 새로 추가하는 것이 아닙니다.
따라서 GROUP BY를 JOIN으로 변경하여 개선하였습니다.
최종 개선한 쿼리
최종적으로는 서브쿼리로 JOIN하는 것이 아니라 travelogue_tag와 직접 JOIN하는 것으로 결정하였습니다.
SELECT
t.id,
t.author_id,
t.created_at,
t.deleted_at,
t.like_count,
t.modified_at,
t.thumbnail,
t.title
FROM
travelogue t
JOIN
travelogue_tag tt1 ON tt1.travelogue_id = t.id AND tt1.tag_id = 2
JOIN
travelogue_tag tt2 ON tt2.travelogue_id = t.id AND tt2.tag_id = 5
ORDER BY
t.like_count DESC
LIMIT 5 OFFSET 1000;최종 성능 측정
최종적으로 실행 시간을 정리하면 다음과 같습니다.
1. like_count 인덱스를 드라이빙 테이블로 삼는 실행 계획 (OFFSET이 0인 경우)
약 2ms 소요
-> Limit: 5 row(s) (cost=1.98e+6 rows=5) (actual time=0.275..1.89 rows=5 loops=1)
-> Nested loop inner join (cost=1.98e+6 rows=5) (actual time=0.275..1.89 rows=5 loops=1)
-> Nested loop inner join (cost=990318 rows=5) (actual time=0.113..1.8 rows=35 loops=1)
-> Index scan on t using idx_travelogue_like_count (cost=0.0326 rows=5) (actual time=0.0326..1.07 rows=440 loops=1)
-> Covering index lookup on tt1 using idx_travelogue_tag_tag_travelogue (tag_id = 2, travelogue_id = t.id) (cost=1 rows=1) (actual time=0.00154..0.00156 rows=0.0795 loops=440)
-> Covering index lookup on tt2 using idx_travelogue_tag_tag_travelogue (tag_id = 5, travelogue_id = t.id) (cost=1 rows=1) (actual time=0.00222..0.00226 rows=0.143 loops=35)2. like_count 인덱스를 드라이빙 테이블로 삼는 실행 계획 (OFFSET이 1000인 경우)
약 700ms 소요
-> Limit/Offset: 5/1000 row(s) (cost=1.98e+6 rows=5) (actual time=830..832 rows=5 loops=1)
-> Nested loop inner join (cost=1.98e+6 rows=1005) (actual time=4.37..832 rows=1005 loops=1)
-> Nested loop inner join (cost=990423 rows=1005) (actual time=3.99..808 rows=11890 loops=1)
-> Index scan on t using idx_travelogue_like_count (cost=5.4 rows=1005) (actual time=3.8..637 rows=132407 loops=1)
-> Covering index lookup on tt1 using idx_travelogue_tag_tag_travelogue (tag_id = 2, travelogue_id = t.id) (cost=1 rows=1) (actual time=0.00117..0.00119 rows=0.0898 loops=132407)
-> Covering index lookup on tt2 using idx_travelogue_tag_tag_travelogue (tag_id = 5, travelogue_id = t.id) (cost=1 rows=1) (actual time=0.00186..0.00188 rows=0.0845 loops=11890)3. travelogue_tag를 드라이빙 테이블로 삼는 실행 계획
OFFSET과 상관없이 약 140ms 소요
-> Limit/Offset: 5/1000 row(s) (actual time=156..156 rows=5 loops=1)
-> Sort: t.like_count DESC, limit input to 1005 row(s) per chunk (actual time=155..156 rows=1005 loops=1)
-> Stream results (cost=312702 rows=166022) (actual time=0.554..152 rows=7396 loops=1)
-> Nested loop inner join (cost=312702 rows=166022) (actual time=0.548..148 rows=7396 loops=1)
-> Nested loop inner join (cost=199713 rows=166022) (actual time=0.54..113 rows=7396 loops=1)
-> Covering index lookup on tt1 using idx_travelogue_tag_tag_travelogue (tag_id = 2) (cost=17089 rows=166022) (actual time=0.516..16.9 rows=88757 loops=1)
-> Covering index lookup on tt2 using idx_travelogue_tag_tag_travelogue (tag_id = 5, travelogue_id = tt1.travelogue_id) (cost=1 rows=1) (actual time=961e-6..989e-6 rows=0.0833 loops=88757)
-> Single-row index lookup on t using PRIMARY (id = tt1.travelogue_id) (cost=0.581 rows=1) (actual time=0.00452..0.00455 rows=1 loops=7396)최종 성능 개선 결과, 최대 1445ms에서 2ms로 개선하여 최대 약 722배 개선하였습니다.
결론
마지막으로 드라이빙 테이블을 무엇으로 삼을지에 대한 결정이 필요했습니다. OFFSET에 따라 더 빠른 실행 계획이 달라질 수 있기 때문에 특정 임계값을 기준으로 STRAIGHT_JOIN을 통해 직접 실행 계획을 지정할까 고민하였습니다. 하지만 결론적으로는 옵티마이저에게 직접 실행 계획 선정을 맡기기로 결정하였습니다.
그 이유는 다음과 같습니다:
- 테스트 데이터와 실제 데이터의 양상 차이: 예를 들어 실제 환경에서 특정 태그가 인기가 많아 해당 태그에 데이터가 몰리는 경우, travelogue_tag를 드라이빙 테이블로 삼더라도 row 개수가 많아져 성능이 어떻게 나올지 예측하기 어렵습니다.
- 임계값 계산의 복잡성: 임계값을 찾는 것도 복잡한 로직을 통해 계산해야 하며, 이는 유지보수에 부담을 줄 수 있습니다.
OFFSET이 큰 쿼리 발생 확률: 무엇보다OFFSET이 큰 쿼리는 자주 발생하지 않습니다. 현재 페이지의 크기가 5개인데,OFFSET이 1000이라는 것은 여행기를 5000개 조회했을 때 나오는 쿼리입니다. 즉 실제 환경에서는OFFSET이 큰 쿼리가 발생할 확률이 매우 낮습니다.
따라서 옵티마이저에게 드라이빙 테이블 선정을 맡기기로 결정하였습니다.
만약 나중에 OFFSET이 큰 쿼리가 자주 발생하고, 옵티마이저가 비효율적으로 드라이빙 테이블을 선정한다면 그때 가서 STRAIGHT_JOIN을 사용하기로 결정하였습니다.
'우테코 > 팀 프로젝트 - 투룻' 카테고리의 다른 글
| [MySQL] INSERT IGNORE 는 데이터 중복 시 왜 새로운 데이터의 삽입을 막을까? (0) | 2024.11.24 |
|---|---|
| 동시성 문제(데드락) 해결기 - X 락인데 왜 공유가 가능하지?????? (2) | 2024.10.30 |